
Regular Expressions are sets of special characters that symbolize search patterns. They look rather strange and esoteric, like it’s super-high-level, brain-exploding voodoo magic, but they’re really not too difficult to learn, and, once you do learn them, you’ll wonder how you ever survived without them.
For the purposes of this article, I’m using Sublime text editor because: a) I love Sublime, and b) it lets you visualize search patterns on the screen so you can see screenshots of exactly what we are talking about.
Depending on what software you use, the regex commands may be slightly different, but, since we are using Sublime, this is a convenient cheat sheet I refer to as needed.
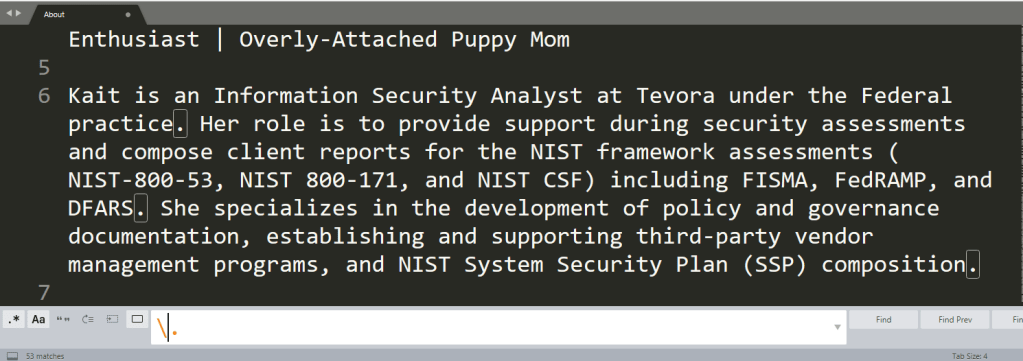
For the fun of it, I’ve gone to CryptoKait’s About Me page and simply copied the entire text and pasted it into Sublime, and then added in some IP addresses as well.
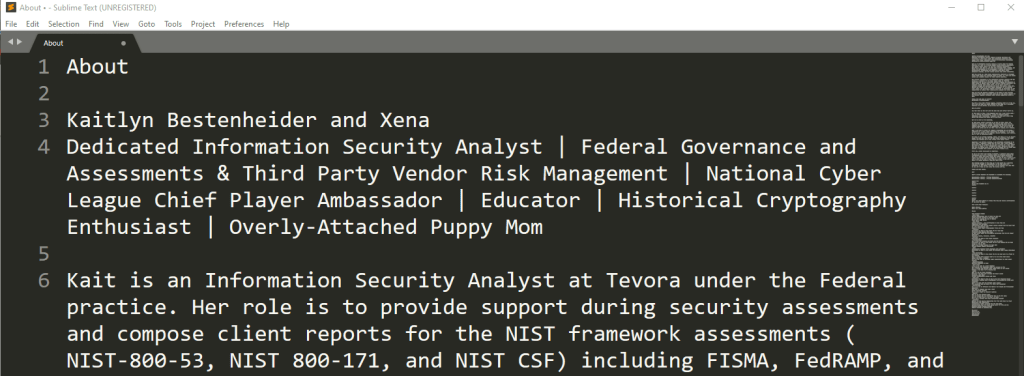
If we hit CTRL+F, or navigate to Find/Find—

—that opens our Find bar at the bottom of the screen.
There are six buttons on the left:

Toggles regex on and off. It is currently toggled on.

Toggles case sensitivity.

Toggles whether to match whole words or partial words.

Toggles whether searches can wrap lines.

Toggles in-selection.

Toggles whether to highlight matches.
BASIC SEARCHES
Now with regex and highlights turned on, let’s demo some regex so you can actually see what’s going on.
Searching for a period by itself is not very useful, as a period represents literally any character (including white space). If we search all for ., you can see that every single character in the document is highlighted.

Searching for ^ finds the beginning of every line.

Searching for $ or \n both will search for the end of a line.
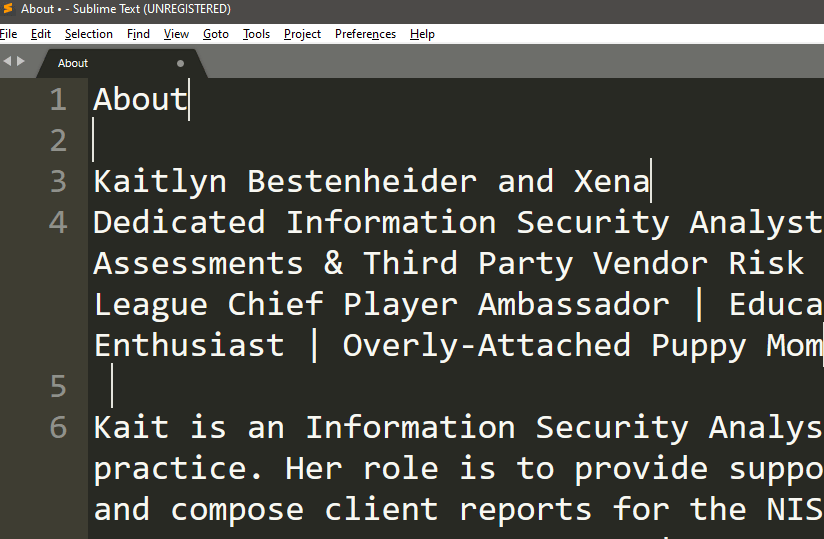
Notice the difference between lines 2 and 5—we can see the difference in white space. Line 5 has a space before the end line while line 2 is a completely blank line.
The next several searches are meaningless on their own as they modify the previous expression/character.
Let’s first search for the letter a.
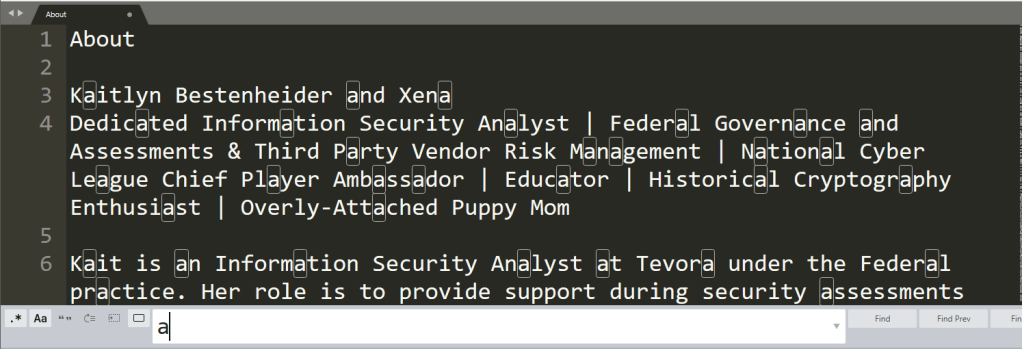
Next, let’s search for the letters an.

We can see our highlighted sections have switched from every instance of a to every instance of an. Let’s go further and add a d, so we search for and.

As expected, we now see every instance of and highlighted. If, however, we add an * to the search and search for and*:

This search is saying search for every instance of an, and if there happens to be a third character, it must be a d. As an example, you can see in line 4 the difference between Analyst and and.
If we search for an., that would be an followed by any character, such as in line 6 where we see different ways an. is resolved, including with white space.

Now let’s search for a double letter—”assessment” has multiple instances of s, so first let’s search for s. Pay attention to some of the words in the screenshot with ss, like “Ambassador”—

—and compare against searching for ss.

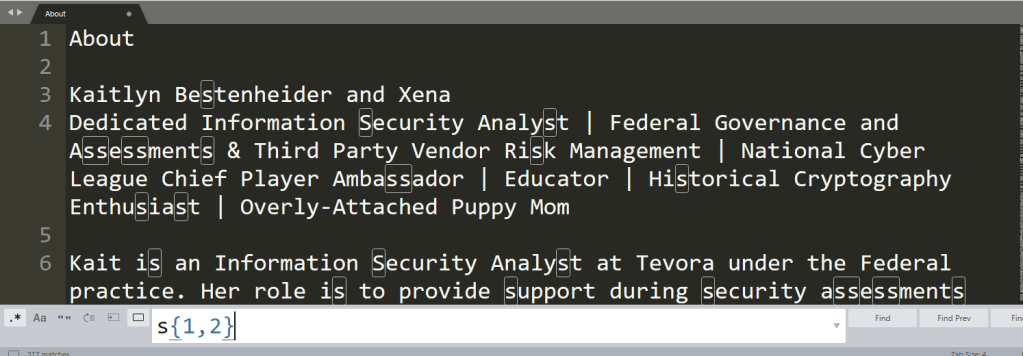
If we know we want to search for ss, we could do this search for ss, or we could use regex to search for a repeating pattern{x} where the indicated pattern will be repeated x times.
s{1} is a rather useless pattern as it searches for every instance of 1 s, much like just searching for s.

s{2} searches for every instance of ss.

s{1,2} searches for every instance of s over a range of 1-2 times.
If we add in a ?, that will toggle whether the search is greedy or not. Compare the word assessment in the above screenshot with the one below.
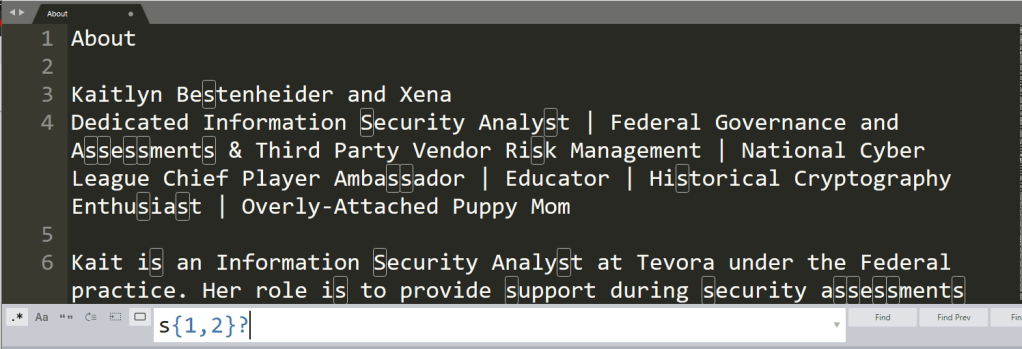
Adding the ? changes whether the lower or higher range takes precedence in the search.
And using a + means to repeat the previous character from 0 to an infinite number of times.
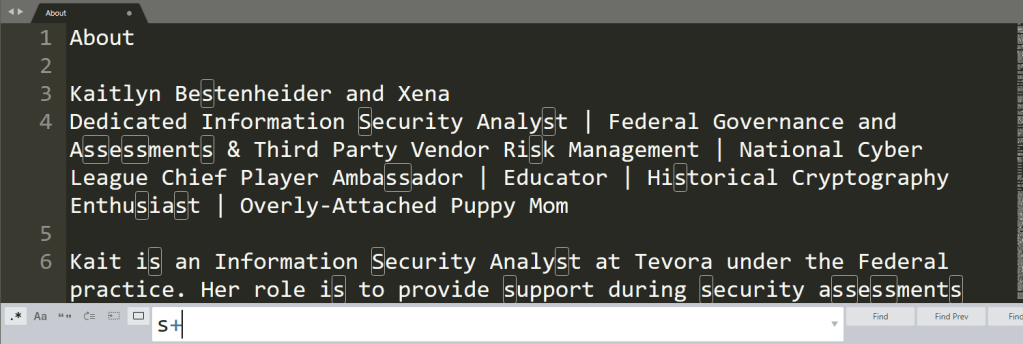
CLASSES
Before we move into the grit, let’s cover character classes—being able to search for, say, all uppercase letters, all letters, all numbers, all special characters.
Let’s start with searching for all white space, which can be typed as \s or [[:space:]].

Or perhaps we are interested in searching just for punctuation [[:punct:]].

Upper case letters are \u or [[:upper:]] (make sure you have case-sensitivity turned on; otherwise, the case searches won’t differentiate).
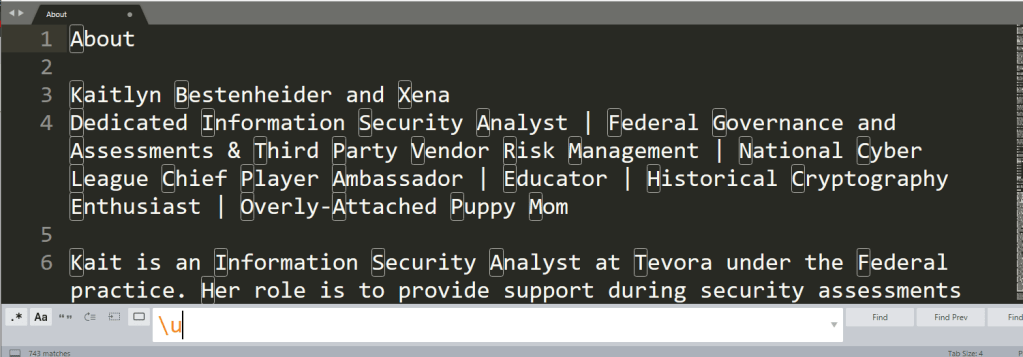
Lowercase letters are \l or [[:lower:]] (again, careful with the case-sensitivity button).

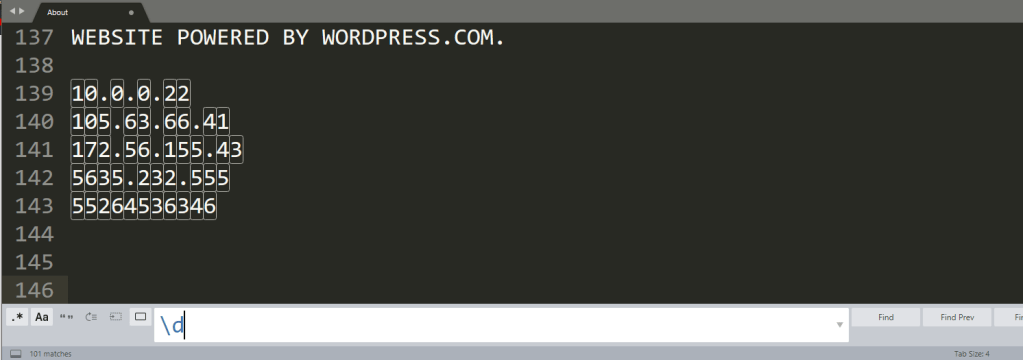
And searching for numbers or digits: \d or [[:digit:]].
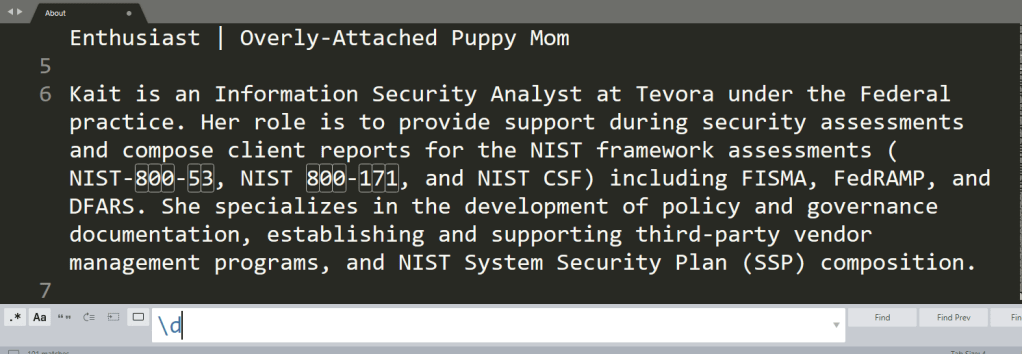
Also of interest may be searching for control characters: [[:cntrl:]]. In this screenshot, just the end line characters (\n) are highlighted.

A word on control characters: These are the normal control/escape characters you see elsewhere. Useful, for example, if you actually want to search for a period, you can escape it as \..
NEGATION
We can use negation by using ^ or capitalized shortcuts.[^[:digit:]] or \D says to search for everything except digits.

\U or [^[:upper:]] both mean to search for everything except for capital letters.

COMPLEX SEARCHES

(\d{1,3}.){3}[[:digit:]]{1,3}
That’s a rather needlessly complicated and sloppy way of searching for IP addresses.
The () groups things together, so (\d{1,3}.) is all one pattern of:
(\d{1,3}– a digit of 1-3 characters in length.)– followed by a literal period{3}– and this is repeated exactly 3 times[[:digit:]]– followed by a digit{1,3}– with a range of 1-3 characters in the digit
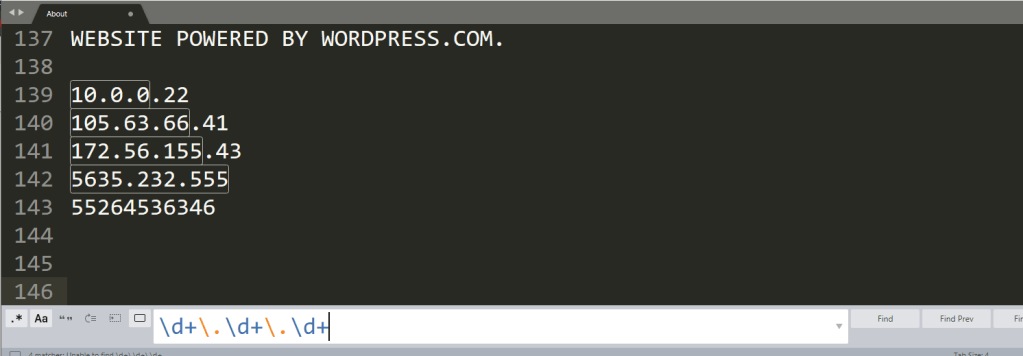
We could break that up a bit more simply into \d+.\d+.\d+.\d+.

That’s still a sloppy way of searching for IP addresses, but it generally works and is an easy pattern to remember.
\d searches for a digit.
+ means one or more of the previous pattern, in this case \d.

\. is the escape character to mean we’re actually looking for a literal period and not the regex symbol for any character possible.



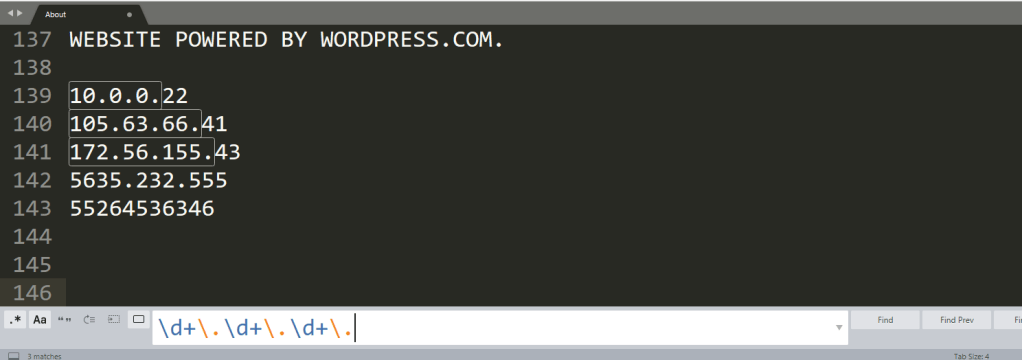

It really does look like evil magic when you’re first looking at regex, but I hope this is displaying just how useful it is. You can get far more complicated than what is displayed here, but this should be enough to set you on the road to becoming a regex master.

